第6回 AIシステムトレード開発
国立国会図書館 関西館に行ってきました。
その中からLSTMの項を全部コピーしました。
自然言語処理の本も、多数読みました。
東京から取り寄せた予約したため、今週末にまた行ってきます。
まったく本屋で見たことのないものも多数あり、
すべて書籍名をノートしてきました。
もうAI関係の図書を買いに一般本屋に行くのを辞めます。
PS.
昼食も安く、コロナ禍ですが空いていました。
こんなんが無料で使えるなんて、日本国民はうらやましい。
本論
ここからが今日の本論・・・
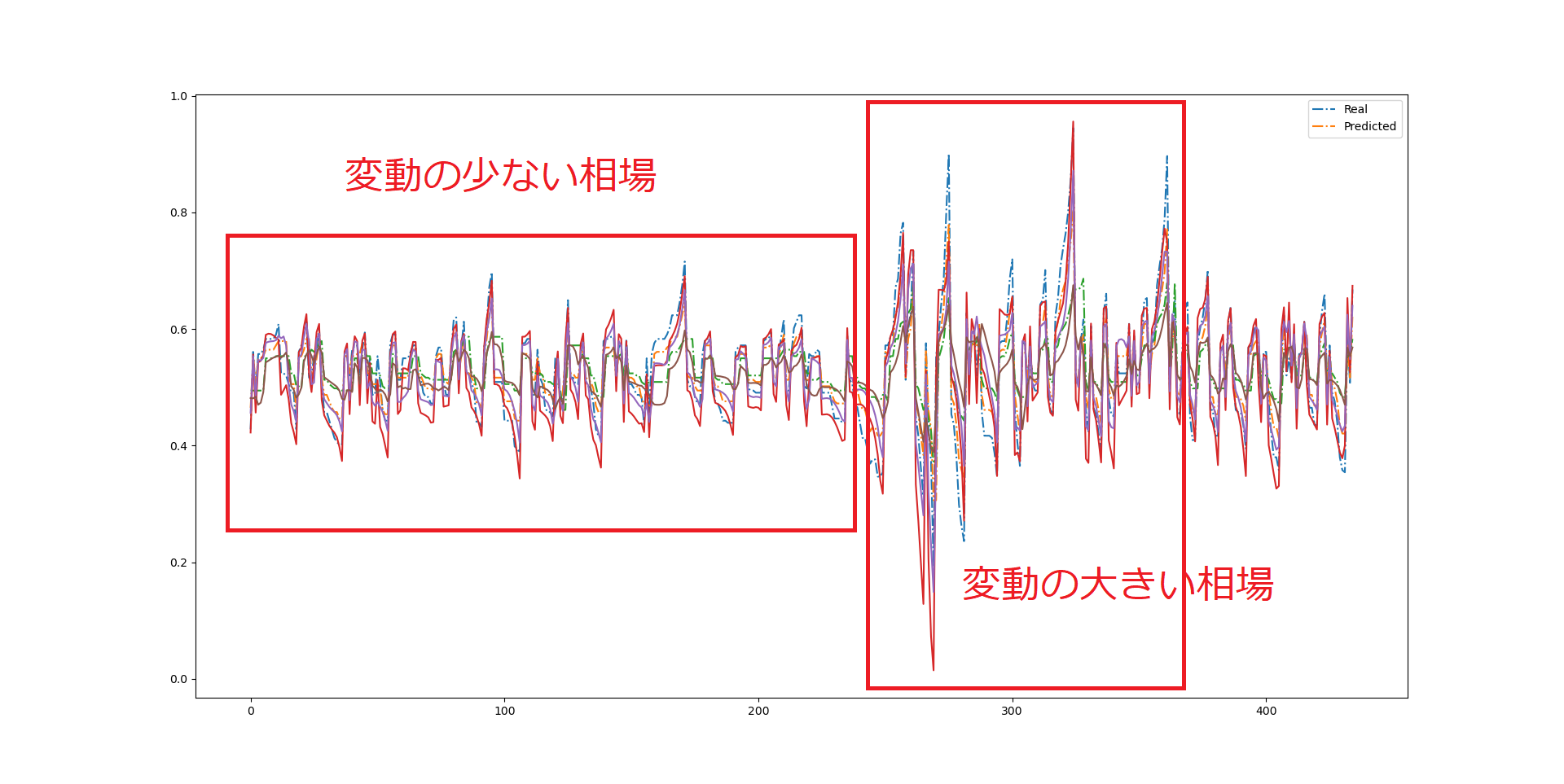
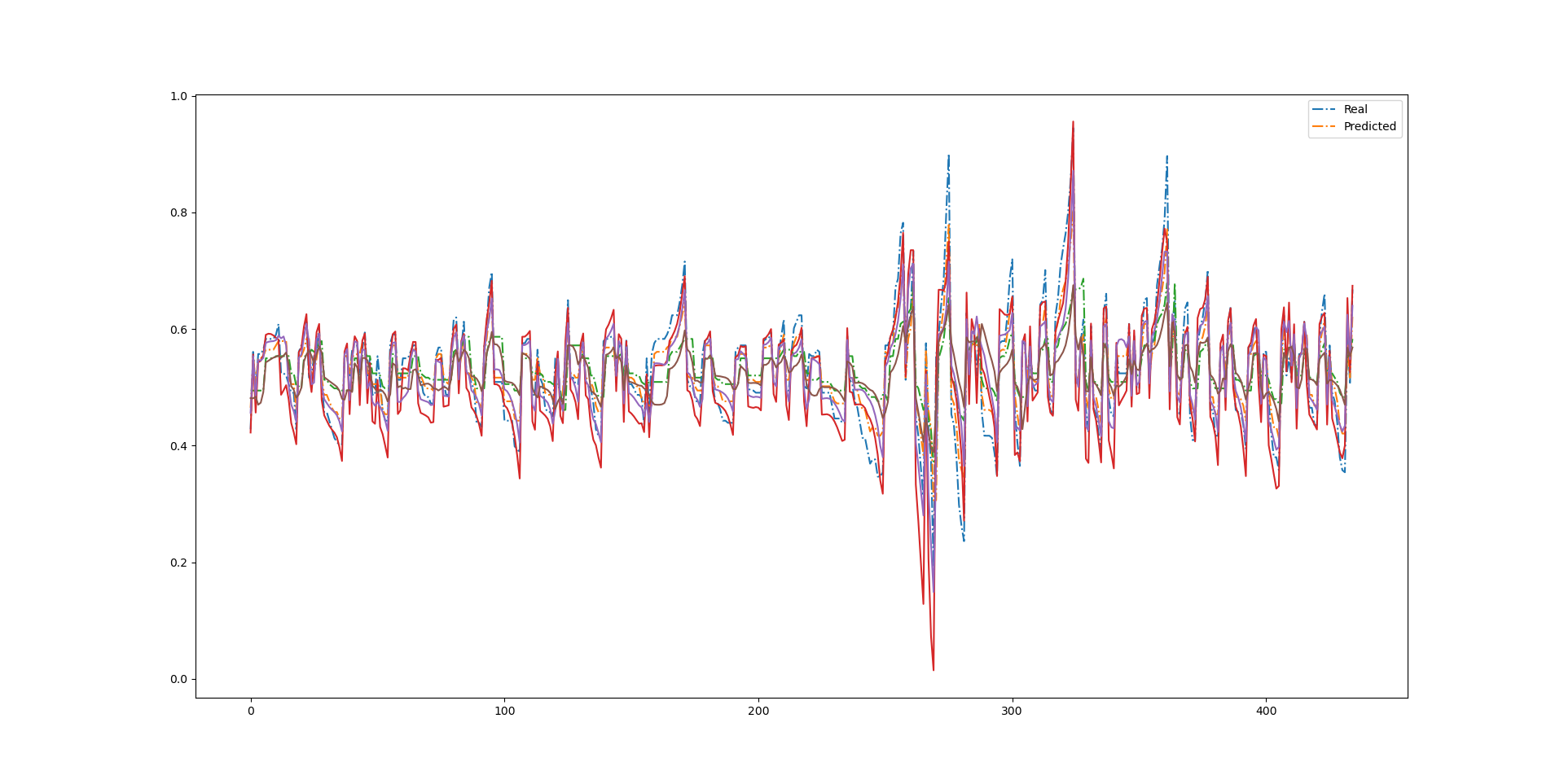
とりあえず、予想と正解の比較データをチャートにしてみた。
P&Fチャートを数列にしたものを、0-1の範囲で標準化したので、
どうしても変化の振れ幅の大きいデータに規格化されてしまっている。
どっちかというと、そういう異常なデータはトリミングしてしまった方がいいだろう・・・
KERASの処理
a1は教師データx
a2は教師データy
最初、fitとかtransformが、分からへんかったが、ようやく意味が分かった。
要するにfitで統計を計算して、transformで実際のデータに反映する。
今回の場合は、fitを使ってa1の教師データで計算させて(数の少ないa2の方は使わない)
transformでa1,a2に反映させると良いだろう...
それにしてもAIでは、やはりデータの素性というものを吟味しなくてはいけない。
下記の例でいえば、前半と後半では相場の変化量が異なるため、
同じ学習データとして扱ってはならない気がする。
しいて言えば、2つのデータで異なる学習機を作っておき、
それを何らかの運用ルールで切り替えるというような、
少し複雑な処理が必要ではないかと思う。