第7回 AIシステムトレード開発
なんとなく完成した
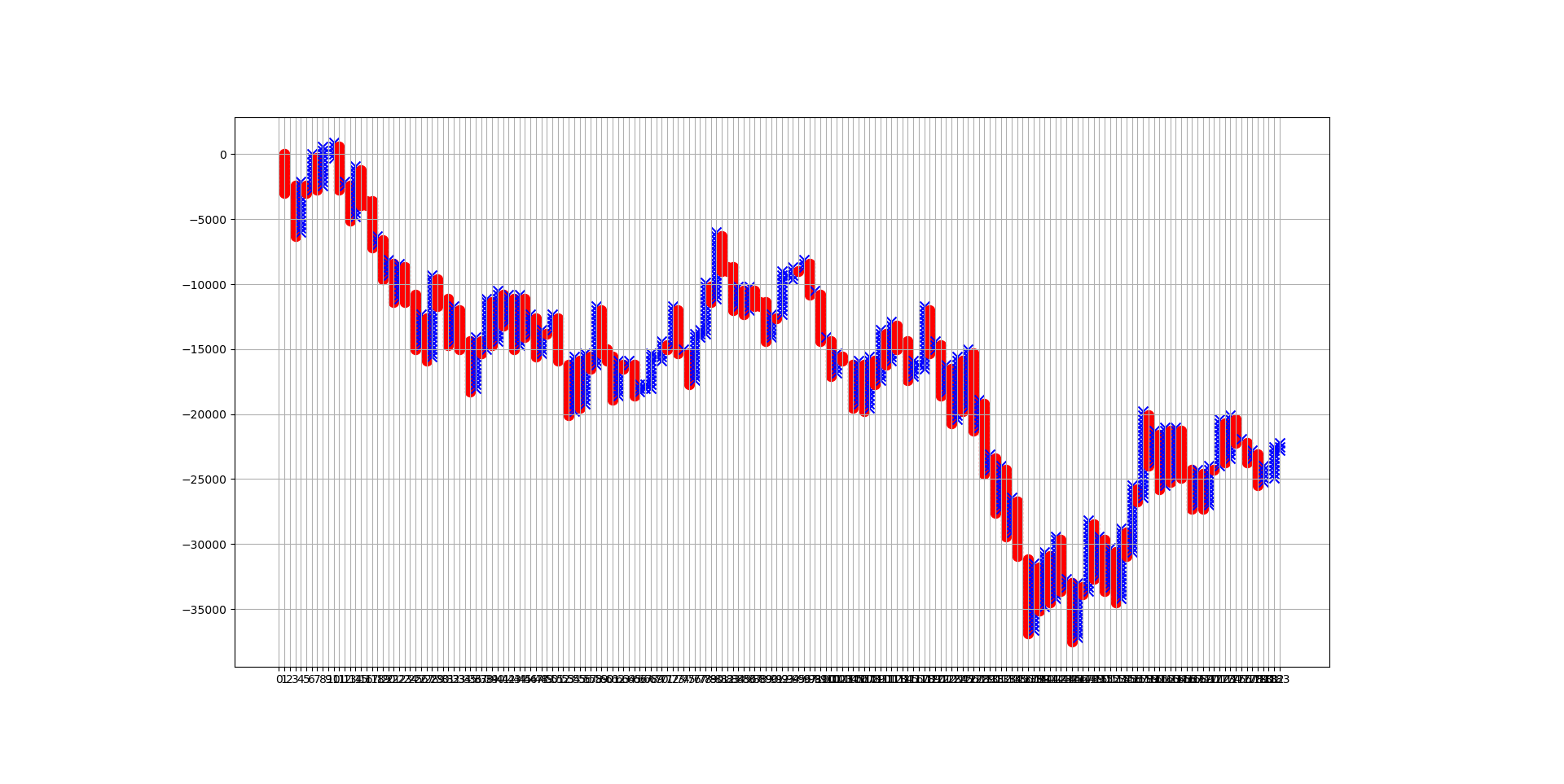
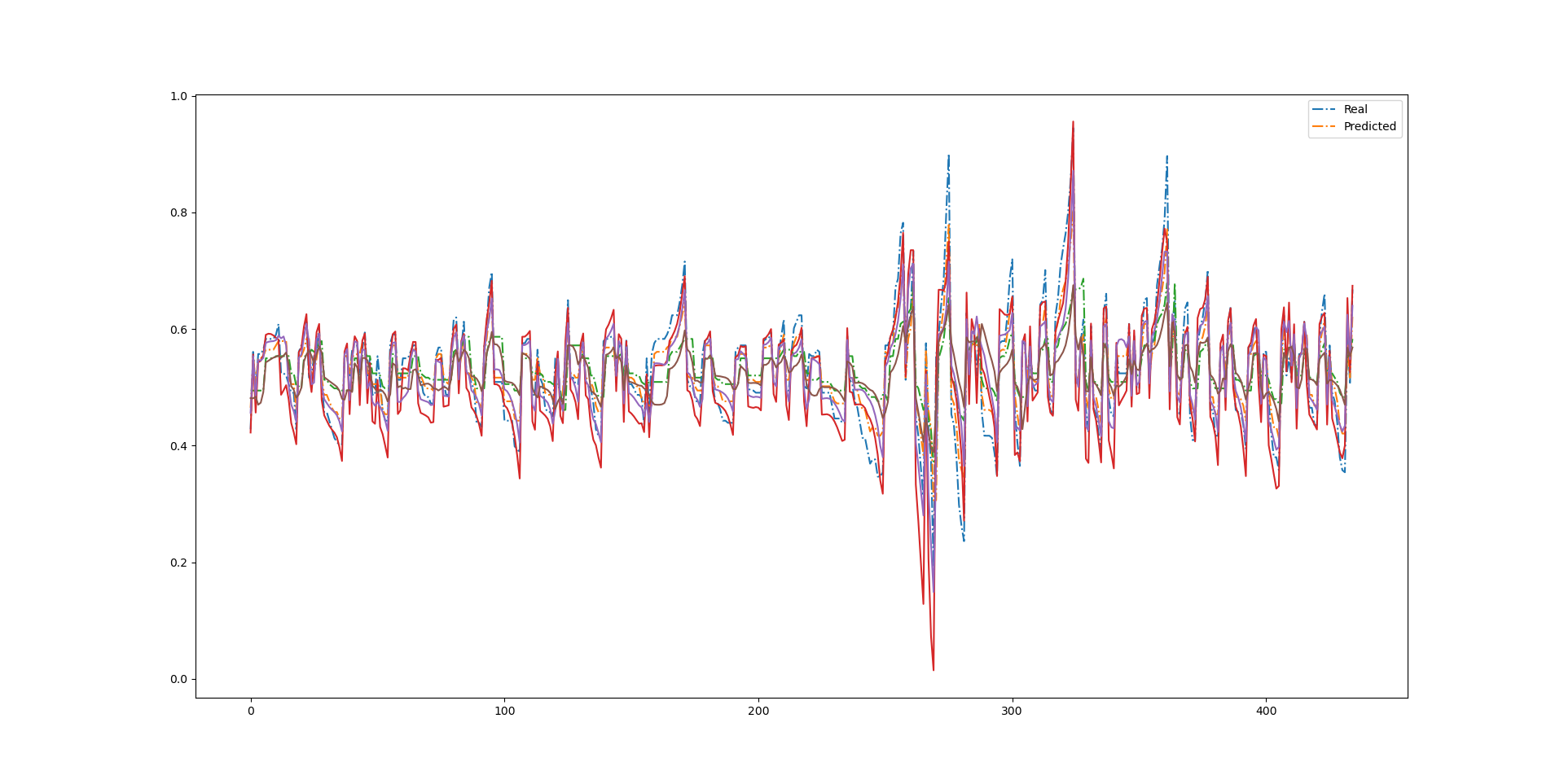
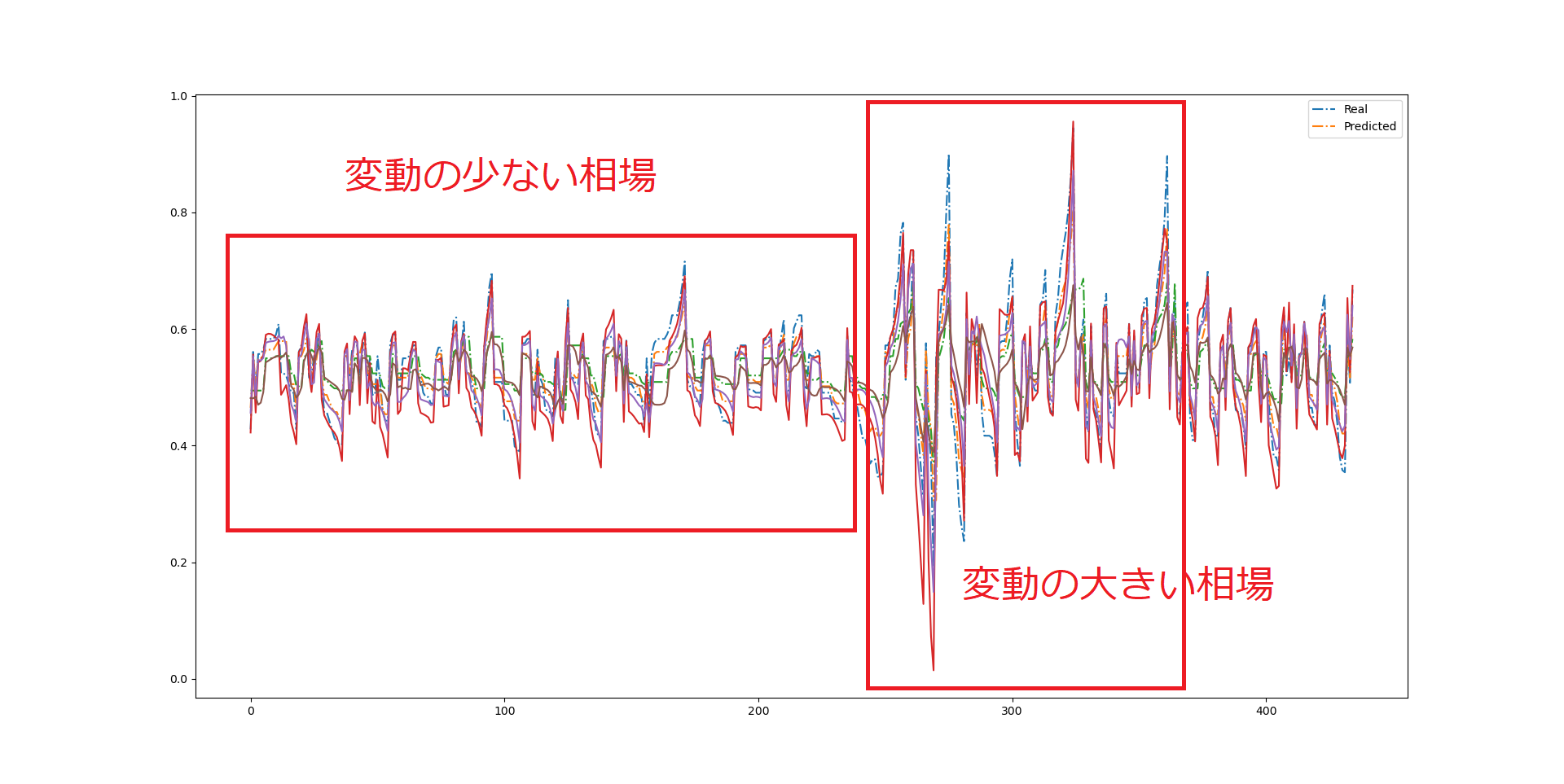
P&Fチャートを使ったAI予測結果を示す。
真値
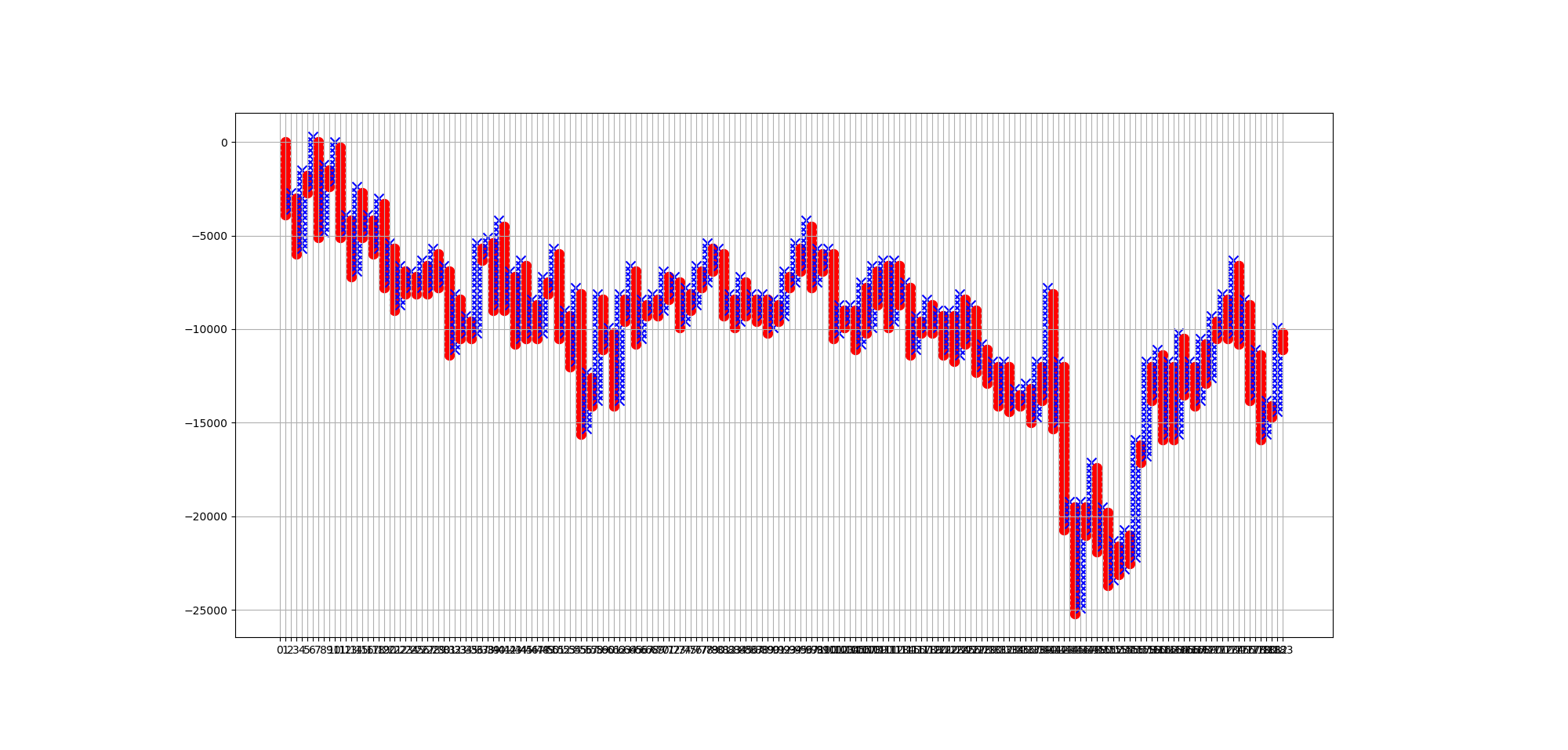
AI予測
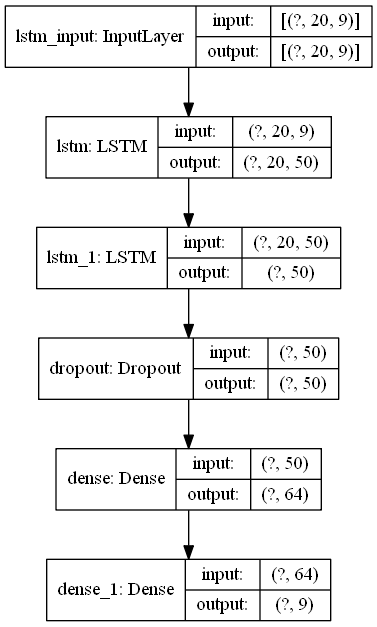
モデル
- 入力ベクトルは下記の9つとした。
- pips 0.0005から0.0013まで、0.0001づつ増やしたPFチャート
- タイムスパン history_points = 20
- 結局はLSTMを2層使っている
- 入力ベクトル 9 + 時間ベクトル 20という感じ
- ほぼ強引に一致させた感じである
- ハイパーパラメータの調整が難しい
第6回 AIシステムトレード開発
国立国会図書館 関西館に行ってきました。
その中からLSTMの項を全部コピーしました。
自然言語処理の本も、多数読みました。
東京から取り寄せた予約したため、今週末にまた行ってきます。
まったく本屋で見たことのないものも多数あり、
すべて書籍名をノートしてきました。
もうAI関係の図書を買いに一般本屋に行くのを辞めます。
PS.
昼食も安く、コロナ禍ですが空いていました。
こんなんが無料で使えるなんて、日本国民はうらやましい。
本論
ここからが今日の本論・・・
とりあえず、予想と正解の比較データをチャートにしてみた。
P&Fチャートを数列にしたものを、0-1の範囲で標準化したので、
どうしても変化の振れ幅の大きいデータに規格化されてしまっている。
どっちかというと、そういう異常なデータはトリミングしてしまった方がいいだろう・・・
KERASの処理
a1は教師データx
a2は教師データy
最初、fitとかtransformが、分からへんかったが、ようやく意味が分かった。
要するにfitで統計を計算して、transformで実際のデータに反映する。
今回の場合は、fitを使ってa1の教師データで計算させて(数の少ないa2の方は使わない)
transformでa1,a2に反映させると良いだろう...
それにしてもAIでは、やはりデータの素性というものを吟味しなくてはいけない。
下記の例でいえば、前半と後半では相場の変化量が異なるため、
同じ学習データとして扱ってはならない気がする。
しいて言えば、2つのデータで異なる学習機を作っておき、
それを何らかの運用ルールで切り替えるというような、
少し複雑な処理が必要ではないかと思う。
第五回 AIシステムトレード開発
参考資料
https://math.uni.lu/eml/projects/reports/2020_Summer/DiasMoreira.pdf

#進捗
とりあえずKERASを使って、それらしい計算まで出来るようになった。
時系列分析のため、LSTMというのを使っている。
今回はpoint & figureをベースとして、入力ベクトルには32個のパラメータを割り当てている。
- 最初に適当な4本足データをCSVで取ってくる。
- 次にPOINT&FIGUREの数列に加工する。
- PFF1,PFF2,PFF3というのが、PFFを時間軸で数列化したものだ。
- PF数列は指定日までを時系列に推移させて計算し、それをケツから使っている
- ケツ[0]が予想すべきデータで、ケツ一個手前[-1]から[-n]までが予想に使うデータである
- データ長は分割数が小さいほど、データ数が少なくなるように配分している
- KERASには、全データ範囲で0,1になるように変換したものを突っ込んでいる
AI部分のコードはパクっただけ。
内容ははっきり言って、何にも分かっていない・・・
いちおう、糞リポジトリを置いておく
煮るなり焼くなり、好きにしやがれ!!
NURO光にぬろっと切り替えた話
最近、NAS(DJ218+)でサーバーを立てて何か
こちょこちょしようかと思って、随分と悩んでいたのだが・・・
どうやらOCN光では、やはりポート開放を諦めないといけないとわかる。
そこで2021/1月に2年縛りから解放されるというので、
思い切ってネット環境をNURO光に切り替えました。
来週に工事があり、年内には開通できそうです。
NUROに切り替えた暁には、DS218のサーバーを公開して
まずやりたいこととしては・・・
1)REDMINEのオープン
→ これは家と会社でそれぞれ使っているものを共通化したい
2)5か国語辞書
→ これもWEB-APP化までは出来ているが、まだWEBサービスとして公開できていない
3)WORDRESS
→ これからのAIアプリ公開に向けて、先ずはサーバーを立てることをやってみたい
そんな訳で、最近はいったん色々なWEB開発を停止して、Deep Learningの勉強に
本腰を入れています。
AIトレードもどうも今一歩のところで、AI理解不足の感が否めず、
年内は進展はなさそうです。
さて、コロナ禍ですが、お正月は親戚イベントは無になりました。
ゆえに、来週に愛車のスノータイヤを新調して、どこかに冬はドライブでも
行こうかなと考えています。
何十年ぶりか、またスキーを始めてみようかなどとも考えています。
というわけで、最近はポセイドン石川のYOUTUBEにハマっています。
2020振り返り
個人的にこの1年の出来たことを書き留める
- WEB開発 → 一通りのところまで階段は登れた → さくさくと仕事のDBアプレは作れるようになった
- スマホアプリ → ICONIC+ANGULAER → 道筋をつけることは完了した
- 心身鍛錬 → REMOTE体制+散歩+夜中ダイエット、左右バランス → 軌道に乗せられた
- REMOTE → 自宅OFFICEのノーストレス化(冬場対策) → ほぼ軌道に乗ることが出来た
- ベッド廃棄 → 部屋の効率化、UP-DOWNデスク,ローリング椅子2個、腕立て
- 武道調べ → 合気道、八光流、詠春拳 → 調査を終了
- 山コミュ → 完全FACEBOOKで不動の地位を確立した
- 仕事 → 7月から完全部署移動 → ストレス払拭
- G検定 → 無事に合格
Point and Figure データモデル化
とりあえずPYTHONのソースを見つけたので、参考にさせていただくこととした。
マーケットデータは前に参考にさせていただいたソースのものを使うことにした。
テスト
- EURUSDの日足データから、P&Fの元になる数列を入手した。
- ブロックの基準数(セル高さ)は、全範囲の(MAX-MIN)/200とした。
- データ長さは、圧縮前5000行だったが、P&F数列は531となった。
試行錯誤
ブロック基準数とデータ圧縮
いまP&Fチャートの特徴をよくよく考えてみると、これはデータを圧縮する方法だと気づく。
その際に基準数を大きくすると、おそらくデータ長さは小さくなると考えられる。
一般的に為替チャートは、基準足の長さによって、日足、週足、月足というふうに、データの粒度が変わってくる。しかしながら、P&Fチャートではトレンドが転換した場合のみにね次の足に更新されるという概念であるため、時間の更新に対して一律に足が更新されるわけではない。
マルチタイムフレーム分析
また一般的なテクニカル指標であれば、基準足に対して、複数の時間尺度を用いて、総合的に相場の局面を判断することが一般的であり、マルチタイムフレーム分析という手法が存在する。
ブロックの基準数を可変すると、データ長さが変わる特性があることから、P&Fにおけるマルチフレームの概念については、複数のブロック基準数をもとに決定するマルチブロック分析が有効と考えられる。
AIアルゴリズム
また、一般的な時系列データに対するAI学習の一般論として、過去のデータの影響を考慮する再帰的学習(リカレントネットワーク)が使われるが、これはレンジ相場のような周期的な変動の場合には有効と考えられる。しかしながら、為替変動の場合はテクニカル的な重要サイン(ブレイクアウトを起点)によるトレンド変化を捉えることが最も重要と考えられるため、再起的な学習よりはパターンの組み合わせ的な条件判断が要求される。AI学習の観点からも、マルチブロックのパターン分析を行う方が理にかなっていると考える。(そもそもRNNに関しては、通常のAI分析に対して計算コスト的にも厳しい状況が想定される。)
今回はいろいろなハイパーパラメータを構成する因子の中に、複数のブロック基準数も加えて、パラメータのチューニングをしてみようかと思う。
モデル
PFの特徴をみると、以下のことがわかる。
- ×と〇は常に繰り返されている
- ×→〇の変化では、一段下から始まる
- 〇→×の変化では、一段上から始まる
この特徴は、全くもって無視しても構わないことになる。
とりあえず下記のP&Fチャートであれば、
×の数をプラス、〇の数をマイナスの数値におきかえると、
このチャートは、下記の数列に等しくなる。
12 , -7 , 7 , -5 , 5 , -3 , 12 , -5 , 5 , -5 , 6 , -6 , 3 , -6 , 2

さらに前後の和を取って、
5 , 0 , 2 , 0 , 2 , 9 , 7 , 0 , 0 , 1 , 0 , -3 , -3 , -4 max = 9 , min = -4 , Range = 13
という風に、ダイナミックレンジを下げることができる。
AIで言えば、学習機の感度が上がる方向になる。
ちなみに、もう一回やるのは、ダメな模様
5 , 2 , 2 , 2 , 11 , 16 , 7 , 0 , 1 , 1 , -3 , -6 , -7 max = 16 , min = -7 , Range = 23
そしてAI的には、次の数字が予想できれば、
トレードのポジションの転換点を知ることができる。
P&Fチャートの優れているところは、
このように数列の羅列の中に、ありとあらゆる値動きが
織り込まれている点だ。
というわけで、先ずはモデルの定義が終わったので、
為替データから上記の数列を出すところから、
コーディングすることとする。